The Diversity of Tasmanian Languages
Proceedings of the Royal Society, B Biological Sciences, 2012 DOI: 10.1098/rspb.2012.1842
The Riddle of Tasmanian Languages
Claire Bowern
Recent work which combines methods from linguistics and evolutionary biology has been fruitful in dis- covering the history of major language families because of similarities in evolutionary processes. Such work opens up new possibilities for language research on previously unsolvable problems, especially in areas where information from other sources may be lacking. I use phylogenetic methods to investigate Tasmanian languages. Existing materials are so fragmentary that scholars have been unable to discover how many languages are represented in the sources. Using a clustering algorithm which identifies admixture, source materials representing more than one language are identified. Using the Neighbor- Net algorithm, 12 languages are identified in five clusters. Bayesian phylogenetic methods reveal that the families are not demonstrably related; an important result, given the importance of Tasmanian Aborigines for information about how societies have responded to population collapse in prehistory. This work provides insight into the societies of prehistoric Tasmania and illustrates a new utility of phylogenetics in reconstructing linguistic history.
Claire Bowern, whom I was lucky to meet at the 19th International Conference of Historical Linguistics in Nijmegen, Holland, in August 2009, and who has been my Facebook friend ever since, is famous for her defense of traditional comparative method as a viable tool in the historical linguistics of aboriginal Australian languages. This paper is therefore coming as a little bit of a surprise because it is chock full of statistical methodologies and data visualizations derived from quantitative biology and population genetics. Just by leafing through Bowern’s paper makes one forget that it is about languages and not about genes. Some biological metaphors seem fortuitous, as in
“Linguists consider the boundary between languages and dialects often difficult to define in absolute terms. In this respect, languages are similar to biological species” (Bowern 2012, 2).
What can be defined in absolute terms?
Others are interesting and quite appropriate:
“The aims are to identify the number and composition of discrete linguistic units (languages) in the data, to determine whether they are demonstrably related, and if so, in how many families, to classify the wordlists without information about provenance, and to determine levels of admixture within wordlists” (Bowern 2012, 2).
Here the biological metaphor (“admixture”) is applied not to the phenomenon of borrowing of lexical material by one language from another but to the process of mixing and matching wordlists, or lexicographic texts, from different dialects by 19th century recorders of the Tasmanian language. Ironically, the very metaphor of “evolutionary trees” in 19th century biology may have originated in the European (monastic) tradition of comparing and organizing the different versions of the same religious or legal text (Atkinson, Quentin, and Russell D. Gray. 2005. “Curious Parallels and Curious Connections—Phylogenetic Thinking in Biology and Historical Linguistics,” Systematic Biology 54 (4): 513-526).
At a time when the application of Bayesian phylogenetics to Indo-European languages – the best studied language family in the world – by scholars with professional affiliations with Australian and New Zealand universities (such as Atkinson, Gray, Bouckaert and others) is facing a strong backlash from the supporters (and increasingly) practitioners of the classical comparative method (Asya Pereltsvaig and Martin Lewis have published on GeoCurrents no fewer than 11 posts against Bouckaert et al. 2012), Australian-born and trained Bowern seems to be reversing the tide by applying similar methods to the least known languages – the poorly attested languages of extinct aborigines of Tasmania.
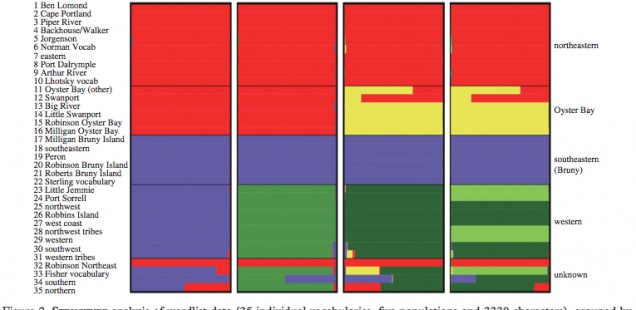
For instance, Bowern applied the STRUCTURE algorithm (see below, Fig. 2) in order to identify source errors in the wordlists and test whether similarities between dialects interpreted by previous scholars as evidence for genetic relationship between Tasmanian languages are in reality products of mixing and matching on the part of the recorders.

Once Bowern purged the wordlists of admixture effects, she used Neighbor Net (see below, Fig. 3) to sort words with similar sounds and meanings into 5 geographical clusters corresponding to 5 tribal divisions among Tasmanian aborigines recognized by ethnologists.

Finally, Bayesian maximum-likelihood analysis was applied to generate a phylogenetic tree of Tasmanian languages and estimate the probability of internal nodes (see below, Fig. 4).

The analysis showed weak statistical support for all nodes but 4, which gave Bowern reasons to talk about 4 Tasmanian “macrofamilies” – Northeastern, Southeastern-Oyster Bay, Northern and Western. It is unclear why she referred to these divisions as “macrofamilies” instead of “families” considering that a macrofamily is usually a hypothetical language family with low degree of certainty regarding its internal relatedness.
But overall Bowern’s conclusion is rather straightforward – there is no statistical support for ideas such as Joseph Greenberg’s whereby Tasmanian languages are considered as a single family belonging to the hypothetical Indo-Pacific family. From the scanty data that we have, Bowern extracted as much sense as possible to demonstrate that the Tasmanian linguistic situation is more similar to the linguistic situation in Papua New Guinea characterized by high linguistic diversity, rather than to the Australian one defined by the domination of one single language family, Pama-Nyungan, the expansion of which started, according to Bowern, in the mid-Holocene.


