Stability vs. Diversity: A Novel Method for Analyzing Worldwide Linguistic Structures
PLoS ONE 7(9), 2012: e45198. doi:10.1371/journal.pone.0045198
Abstract Profiles of Structural Stability Point to Universal Tendencies, Family-Specific Factors, and Ancient Connections between Languages
Dan Dediu, and Stephen C. Levinson
Language is the best example of a cultural evolutionary system, able to retain a phylogenetic signal over many thousands of years. The temporal stability (conservatism) of basic vocabulary is relatively well understood, but the stability of the structural properties of language (phonology, morphology, syntax) is still unclear. Here we report an extensive Bayesian phylogenetic investigation of the structural stability of numerous features across many language families and we introduce a novel method for analyzing the relationships between the “stability profiles” of language families. We found that there is a strong universal component across language families, suggesting the existence of universal linguistic, cognitive and genetic constraints. Against this background, however, each language family has a distinct stability profile, and these profiles cluster by geographic area and likely deep genealogical relationships. These stability profiles seem to show, for example, the ancient historical relationships between the Siberian and American language families, presumed to be separated by at least 12,000 years, and possible connections between the Eurasian families. We also found preliminary support for the punctuated evolution of structural features of language across families, types of features and geographic areas. Thus, such higher-level properties of language seen as an evolutionary system might allow the investigation of ancient connections between languages and shed light on the peopling of the world.
In human origins research there is a lot of talk about “diversity.” Geneticists have a whole host of statistical tools to measure inter- and intragroup allelic diversity. Biologists interpret the area with the highest levels of biological diversity as the most likely homeland of the species. The neutral model of biological evolution favors change – the more changes are observed in a given territory, the more likely it was occupied the longest. This was one of the powerful reasons why geneticists interpreted high allelic diversity in African populations as a signal of the origin of modern humans in Africa. Selection-based models are rarely seen in human origins research. Selection culls diversity favoring only those traits that increase biological fitness. Skin color variation is one of rare cases when it is trait stability and not trait diversity that is taken as indicator of population age: the dark pigmentation of Sub-Saharan Africans is interpreted as ancestral for modern humans reflecting the long history of hominin occupation of Africa and ultimately the origin of modern humans in Africa. As modern humans presumably fanned out from Africa into higher latitudes, a variety of shades of lightness and darkness evolved in Europe, Asia and the Americas reflecting convergent evolution (Asia and Europe) and regressive evolution back in the direction of the ancestral state (America).
Linguistics has so far painted a different picture. The observed diversity between 6000+ languages is classified into some 250 genealogical units, or linguistic stocks, on the basis of regular sound correspondences, recurring morphological patterns and shared basic vocabulary. The greatest diversity of these units is not in Africa but in the New World (140 stocks) and Papua New Guinea, in the opposite corner of the world from Africa. The relationships between the 250 families are not clear, although various higher-order megaphylas have been proposed (Nostratic, Amerind, Indo-Pacific, etc.). At the same time, linguists have long noticed that a large number of structural patterns beyond sound correspondences, morphological patterns and the basic vocabulary recur in world languages but do not easily cluster into genealogical units. There are areas of the world where these structural patterns show surprising diversity (e.g., all six logically possible types of word order are found in South America) but it is unclear if these forms evolved several times in human linguistic history, if the sharing of the same type means languages stem from the same proto-language, and if all of the attested types evolved from a single prototype characterized by exceptional stability.
The growing interest of linguists in stability vs. diversity is reflected in the article “Diversity and Stability in Language” (The Handbook of Historical Linguistics, edited by Brian Joseph and Richard Janda. London, 2003) by Johanna Nichols, the author of the highly influential volume from the 1990s, Linguistic Diversity in Space and Time (1992). Now, Dediu & Levinson (2012) apply Bayesian statistical packages to assess “stability profiles” of major language families and language areas on the basis of a large set of linguistic traits (see below) from The World Atlas of Linguistic Structures. The authors acknowledge that this analysis will hardly yield immediate implications for historical linguistics. It’s more of a bird’s eye view on what posterior probabilities one could derive from a large set of linguistic features using as many as 12 global datasets. It’s presumed advantage is that the approach yields patterns that are “too big to fail”: if whole language families are considered, stochastic processes such as structural borrowing or feature loss may affect one or two languages but they will not affect the overall “structural profile.”




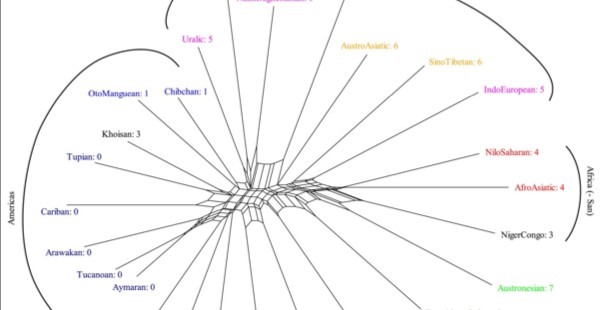
They claim that their 12 datasets yielded essentially the same results. Hence, they posted only one unrooted phylogeny in the main article (see below on the left, Fig. 2) and kept the other 11 in Supplementary Materials. A cursory glance at those other 11 datasets, however, leads one to conclude that each one of them is different (see, e.g., below on the right, Fig. S10, Suppl.Mat.).


If for the dataset on the right, Dediu & Levinson report that Khoisan and Australian are the most divergent among human language families (relative branch length represents that), the dataset on the left don’t show this same pattern.
But for the kind of highly abstract megaanalysis that Dediu & Levinson (2012) produced, their results contain a few interesting and surprising nuggets that seem to make sense.
1. American Indian languages dominate the diagrams and form a closely knit group, with a fewer outgrowths into other world clusters. The world is basically split into American Indian languages and the rest. American Indian languages are, therefore, diverse in the number of stocks and stable in terms of structural features. This is consistent with another recent study.
2. Na-Dene languages cluster with other American Indian languages indicating that Greenberg’s infamous tripartite classification erred not just on the lumping side, but on the splitting side, too.
3. Northern Eurasian languages fall into two clusters – Uralic, Turkic, Mongolic and Indo-European form one, and Chukotko-Kamchatkan, Yukaghir and Tungusic form the other one. The first grouping reinforces some of Nostratic and Eurasiatic thinking but contradicts much of it. The Northern Eurasian (and not West Asian, for example) provenance of Indo-European is consistent with Frederik Kortlandt’s (“The Indo-Uralic Verb,” 2001) view of “Indo-European as a branch of Indo-Uralic which was transformed under the influence of a Caucasian substratum connected with the Maykop culture in the northern Caucasus” confirmed in Matasovic’s recent study reporting that, while there was heavy structural borrowing from Caucasian languages into Proto-Indo-European, some of the structural features of Indo-European languages (e.g., dual number) have “northern Eurasian” affinities. The”‘Caucasian” substrate is Indo-European has support in autosomal genetics. It bolsters the doubts many linguists have over the genetic unity of Mongolic, Turkic and Tungusic. But it reinforces the Paleoasiatic linguistic area with an intriguing turn whereby Tungusic is included in it.
4. Most interestingly, Chukotko-Kamchatkan, Yukaghir and Tungusic gravitate toward American Indian languages, especially North American Algic, Wakashan and Uto-Aztecan.
“The permutation test found that the stability profiles of the American language families are much more similar than expected by chance () and this holds even after controlling for geography (
), a result found using all 5 methods for combining p-values; Table 2 (please note that as discussed in the Methods section, most cases where controlling for geography results in a much lower p-value, are artifacts of our conservative approach of picking the highest combined p-value). Moreover, South American families also form a coherent sub-group (
; 5 methods) even after controlling for geography (
; 5 methods), while North American families form their own subgroup only when not controlling for geography (
, 5 methods and
, 2 methods, respectively). Importantly, the Siberian language families (comprising Chukotko-Kamchatkan, Tungusic and Yukaghir; see Materials S1) group robustly with the Americas (
, 5 methods and, after taking geography into account,
, 5 methods). In particular, Siberia clusters especially with North America (
, 5 methods and
, 4 methods after controlling for geography) and with South America (
, 5 methods, and
, 5 methods when controlling for geography).”
Dediu & Levinson (2012) believe that this fact “fits the general migration patterns inferred from archeology and genetics” without realizing that it provides further support for a growing body of archaeological, genetic and cultural data for a back-migration out of America at the end of the Ice Age, as Siberian languages in their study are firmly nested within the American Indian cluster. The attachment of Tungusic to the same Paleoasiatic cluster parallels the genetic finding of a subset of American Indian mtDNA C1 lineages in Tungusic-speaking Nanaitsy, Oroks and Ulchi (see more here).
4. Yukaghir is not treated as part of Uralic (contra Nikolaeva’s Uralic-Yukaghir proposal), which is consistent with Jaakko Häkkinen’s (“Early Contacts between Uralic and Yukaghir,” in Per Urales ad Orientem. Iter Polyphonicum Multilingue. Festskrift tillägnad Juha Janhunen på hans sextioårsdag den 12 februari 2012. Suomalais-Ugrilaisen Seuran Toimituksia = Mémoires de la Société Finno-Ougrienne 264. Helsinki 2012, 91-101) argument that all the similarities between Uralic and Yukaghir derive from a) contacts between Yukaghir and Samoyedic and b) contacts between Proto-Uralic and Yukaghir and not from common origin of Uralic and Yukaghir.
5. The African cluster is very robust but it quite repeatedly excludes Khoisan. Khoisan consistently clusters next to American Indian language families: between Oto-Manguean and Tupian (S10), between Hokan and Tai-Kadai (S9), between Na-Dene and Austroasiatic (S6), between Oto-Manguean and Afroasiatic (S4), between West Papuan and Hokan (S3, Fig. 2 above). This is consistent with Khoisan being genetic outliers in Africa, with a back-migration of a bulk of Y chromosomes from Asia into Sub-Saharan Africa (hg E) and with some phenotypic features of the Khoisan (epicanthic fold, lighter skin, etc.) that are typical for Eurasia and not Africa.
It is somewhat surprising that such a panoramic study as Dediu & Levinson (2012) failed to detect any clustering of languages around the Pacific Rim. This was one of Johanna Nichols’s findings reported in Linguistic Diversity in Space and Time (1992) that Circumpacific languages (on the New World and Asian/Oceanian sides) share a lot in common in terms of structural features. Bickel & Nichols (“Oceania, the Pacific Rim, and the Theory of Linguistic Areas,” in Proceedings of the 32nd Annual Meeting of the Berkeley Linguistics Society, 2006) confirmed this finding. Bickel & Nichols (2006) also observed that on the Old World side, the Pacific Rim set of features (e.g., polysynthesis/high inflectional synthesis of the verb and n-m personal pronouns) shows “greater variance and general diffuseness” compared to their New World counterparts. This means that Dediu & Levinson’s supertight American Indian cluster appears diluted on the Old World side of the Circumpacific zone. Bickel & Nichols (2006) find an explanation that does not require an out-of-America migration scenario (“Oceania has been inhabited longer than the Americas and domestication occurred earlier there than in the Americas, so the land was already linguistically and demographically saturated when the PR expansion began. In saturated conditions, new linguistic features had less impact and took root less readily”) but, in this, Nichols contradicts herself, as in Linguistic Diversity in Space and Time she noted that our best perspective on the early human language comes from the languages of the Pacific Rim. Hence, these languages were the first ones to enter Asia and the Sahul. This is also consistent with an aspect of Musical Protolanguage Theory whereby polysynthetic languages are the relics of an archaic form of semiosis.



Why are the words for ELEPHANT so similar across EURASIA? I want to share more info
Chinese S ee AH N g
Hakka (south China) S I O N g
Tocharian A ON K A L A M
Tocharian B ON K O L M O
Latvian Z I L O N us
Saami/Lapp S L O NN
Tibetan G L A N
Slavic (MANY languages!) S L O N
Polish (Slavic variant) S “u” O N
Vietnamese C O N VOI
Mongol Z A A N
Japanese Z O S A N